El laboratori de Google (Google Labs) conté una aplicació anomenada Books Ngram Viewer que mostra informació gràfica sobre la freqüència d’ús de determinades expressions en el pla temporal. La informació s’extreu dels corpus que s’han creat a partir de Google Books. Actualment, hi ha corpus creats per a l’anglès, el francès, l’espanyol, l’alemany, el rus, l’hebreu i el xinès. No és possible, per ara, fer cerques per al català; esperem que aviat ho siguin.
Amb Books Ngram Viewer podem delimitar un espai temporal comprès entre l’any 1500 i el 2008, i cercar-hi qualsevol expressió per a un dels corpus disponibles. La gràfica ens mostrarà la freqüència d’ús de l’expressió cercada dins l’espai temporal indicat. Així, si cerquem el mot perestroika dins el corpus d’anglès per al període temporal comprès entre el 1900 i el 2008, podrem veure que es genera una gràfica que mostra que, dins els llibres indexats en aquest corpus, el mot perestroika apareix a partir de la segona meitat dels anys vuitanta i se’n parla poc a partir del 2000.
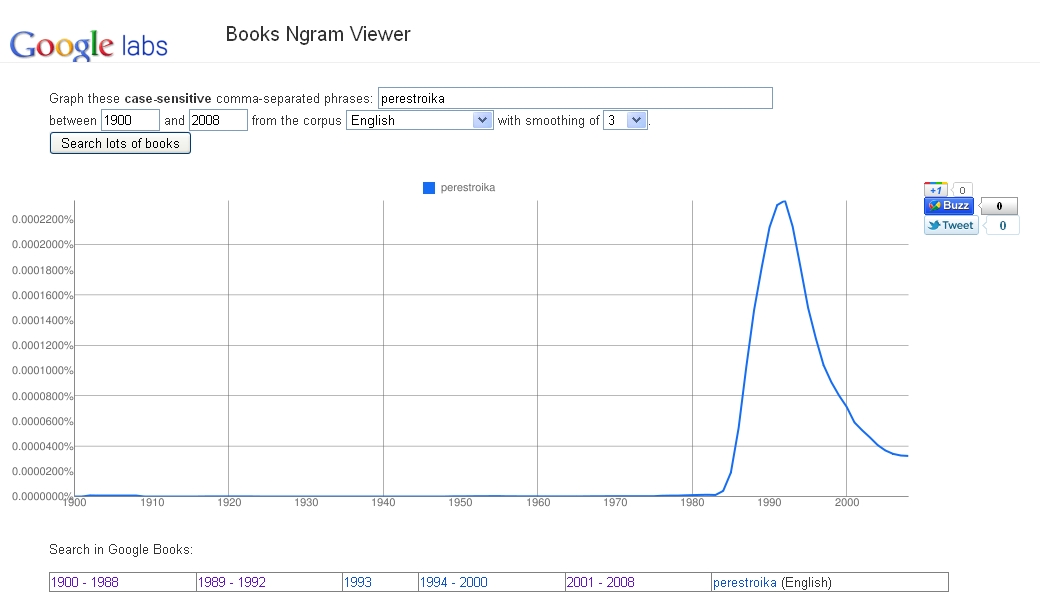
La línia de sota la gràfica ens permet accedir als textos dels llibres indexats en què apareix el mot, agrupats en segments temporals generats automàticament. Fent clic a sobre del segment temporal que ens interessa consultar podrem accedir als textos originals d’on s’han extret les dades.
També es possible comparar la freqüència d’ús de dues o més expressions, separades per comes. Vegem, per exemple, l’ús dels termes sinònims red blood corpuscles, haematids, erythrocytes i red blood cells.
Àngels Egea (Serveis Lingüístics de la UB)