15 febr. 2012
Ja fa uns quants mesos que el Vocabulària va entrar en funcionament. Es tracta d’un portal dels Serveis Lingüístics de la Universitat de Barcelona destinat especialment als membres de la comunitat universitària i que té l’objectiu de contribuir a millorar la qualitat lingüística de les comunicacions universitàries pel que fa a la terminologia mitjançant la publicació periòdica (generalment setmanal) de breus apunts sobre reculls terminològics (diccionaris, vocabularis, etc.) publicats recentment o bé sobre termes o expressions lingüístiques d’ús freqüent en l’àmbit universitari i que s’ha observat que s’usen incorrectament. Cada apunt està etiquetat segons l’àmbit temàtic a què pertany, de manera que els usuaris dels diferents centres de la UB tenen l’opció de consultar únicament els que pertanyen a la seva àrea de coneixement.
A més a més, el portal incorpora una interfície que permet la consulta dels termes inclosos en els vocabularis publicats pels Serveis Lingüístics i també la consulta de l’Optimot per tal que els usuaris puguin resoldre els dubtes terminològics o lingüístics que se’ls presentin i, en el cas que no hagin pogut resoldre’ls, se’ls facilita l’accés a la interfície de consultes en línia Sens dubte.

Àngels Egea (Serveis Lingüístics de la UB i vocal del Butlletí de la SCATERM)
15 oct. 2011
El laboratori de Google (Google Labs) conté una aplicació anomenada Books Ngram Viewer que mostra informació gràfica sobre la freqüència d’ús de determinades expressions en el pla temporal. La informació s’extreu dels corpus que s’han creat a partir de Google Books. Actualment, hi ha corpus creats per a l’anglès, el francès, l’espanyol, l’alemany, el rus, l’hebreu i el xinès. No és possible, per ara, fer cerques per al català; esperem que aviat ho siguin.
Amb Books Ngram Viewer podem delimitar un espai temporal comprès entre l’any 1500 i el 2008, i cercar-hi qualsevol expressió per a un dels corpus disponibles. La gràfica ens mostrarà la freqüència d’ús de l’expressió cercada dins l’espai temporal indicat. Així, si cerquem el mot perestroika dins el corpus d’anglès per al període temporal comprès entre el 1900 i el 2008, podrem veure que es genera una gràfica que mostra que, dins els llibres indexats en aquest corpus, el mot perestroika apareix a partir de la segona meitat dels anys vuitanta i se’n parla poc a partir del 2000.
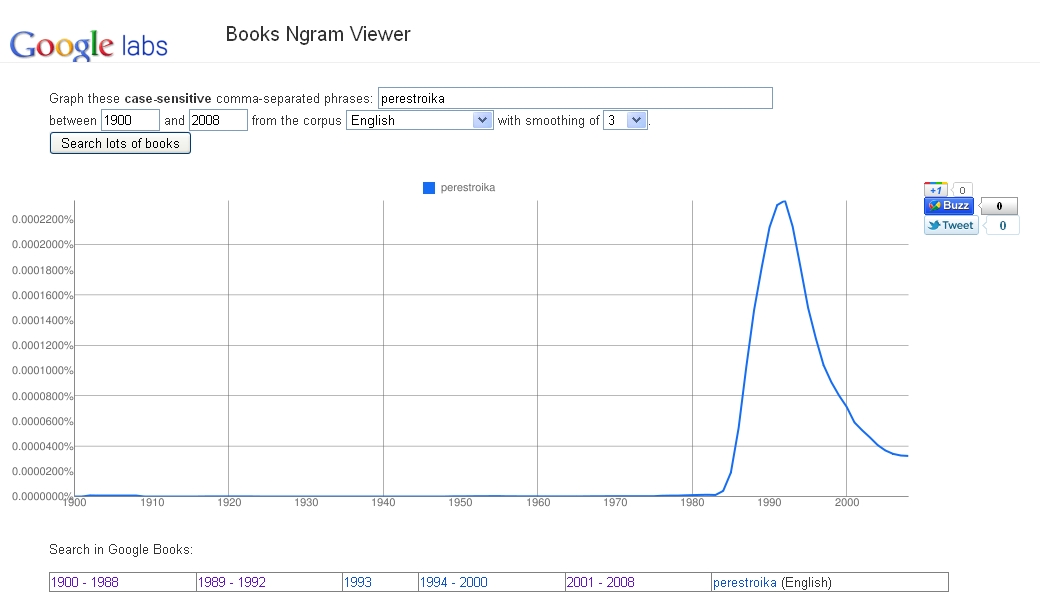
La línia de sota la gràfica ens permet accedir als textos dels llibres indexats en què apareix el mot, agrupats en segments temporals generats automàticament. Fent clic a sobre del segment temporal que ens interessa consultar podrem accedir als textos originals d’on s’han extret les dades.
També es possible comparar la freqüència d’ús de dues o més expressions, separades per comes. Vegem, per exemple, l’ús dels termes sinònims red blood corpuscles, haematids, erythrocytes i red blood cells.
Àngels Egea (Serveis Lingüístics de la UB)
15 ag. 2011
Phraseup* és un eina que permet trobar les col·locacions més habituals d’una paraula gràcies a un algorisme que cerca en els textos disponibles a Internet, independentment de la llengua en què estan escrits. Això és especialment útil quan necessitem saber quins són els contextos sintàctics més habituals d’una paraula o les paraules amb les quals concorre generalment.
Per exemple, si volem saber quines són les preposicions que acompanyen l’adjectiu bel·ligerant podem escriurebel·ligerant* en el quadre de cerca i obtindrem una llista amb el mot bel·ligerant seguit dels tres mots que Phraseup* ha trobat més recurrents en aquesta posició. Vegem-ne un fragment:
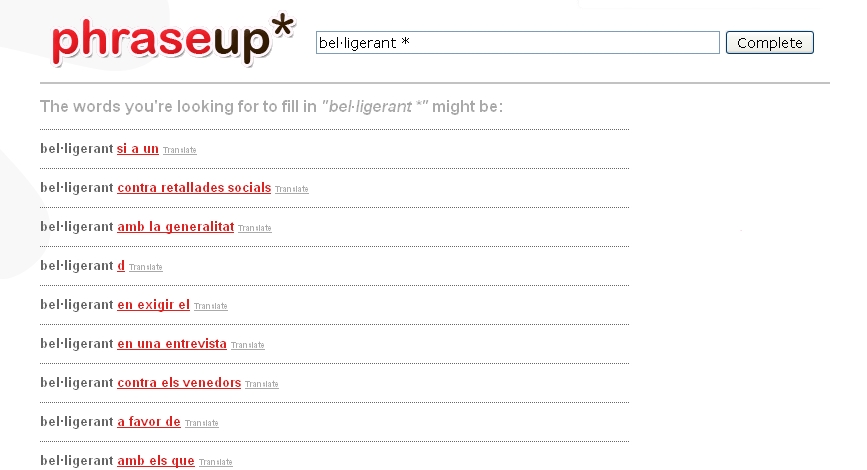
No és possible, ara per ara, accedir als textos que contenen aquests fragments des de Phraseup*, però podem consultar-los des del Google si copiem entre cometes el fragment de la llista per al qual volem trobar els contextos reals («bel·ligerant amb», «bel·ligerant contra», «bel·ligerant en», etc. ). D’aquesta manera podrem saber també quina quantitat d’ocurrències tenim de cada col·locació.
Les utilitats de Phraseup* són diverses: des de trobar aquella paraula que acostuma a acompanyar-ne una altra i que ara no ens ve al cap (cerqueu, per exemple, tenir el do de la* i veureu que aquesta expressió acostuma a anar seguida de ubiqüitat), fins a trobar l’expressió correcta en una altra llengua (cerqueu *the weather like i veureu que va precedit de what’s i no pas de how is). De ben segur, podeu trobar-ne altres.
Àngels Egea (Serveis Lingüístics de la UB)
15 juny 2011
L’Eurovoc és un tesaurus del Parlament Europeu, multidisciplinari i multilingüe, que permet indexar els documents gestionats per les institucions europees. Aquest tesaurus s’ha traduït a vint-i-dues llengües oficials de la UE i a algunes de no oficials.
La traducció catalana, feta al Parlament de Catalunya, inclou una versió adaptada a les necessitats d’aquesta institució. L’Àrea d’Arxiu del Departament d’Estudis Parlamentaris la utilitza des de l’any 2000 com a instrument de descripció per a indexar totes les iniciatives parlamentàries, i compta amb l’assessorament lingüístic i terminològic dels lingüistes del Parlament per a la traducció i l’adaptació dels termes. L’Arxiu s’encarrega també de mantenir i actualitzar aquesta eina i la posa a disposició de qualsevol usuari mitjançant el web que us presentem (https://www.parlament.cat/web/documentacio/recursos-documentals/tesaurus ).

En concret, el web permet consultar la versió traduïda al català de la versió 4.3 de l’Eurovoc europeu i la versió catalana amb el desenvolupament propi —adaptada a la tasca i les funcions del Parlament de Catalunya, amb nous descriptors i no-descriptors. També permet descarregar les versions en PDF i consultar la versió original multilingüe per mitjà d’un enllaç al web oficial de la UE. Finalment, ofereix un document de presentació i un d’ajuda a la consulta.
Agustí Espallargas (Serveis d’Assessorament Lingüístic del Parlament)
19 abr. 2011
Com afirma el mateix Portal Jurídic de Catalunya, «l’accés de la societat a les normes vigents és un dels principis bàsics de la transparència i la qualitat democràtica». Efectivament, la Generalitat de Catalunya, amb la voluntat de complir aquest principi, va obrir, a mitjan mes de desembre passat, aquest Portal (https://www20.gencat.cat/portal/site/portaljuridic), que és, sobretot, una bona eina per a consultar totes les normes amb rang de llei, els decrets i les ordres publicades dins la «secció I» del Diari Oficial de la Generalitat de Catalunya des de l’any 1977.
Així mateix, inicialment s’hi poden consultar els textos consolidats de totes les normes amb rang de llei de Catalunya; però, en el cas dels decrets, només des de l’1 de gener de 1999. Aquesta normativa es complementa amb una selecció de normes estatals consolidades en català, elaborades pel servei LexCat del Departament de Justícia, i una selecció de normativa europea que, en una primera fase, es limita a textos de tractats constitutius de la Unió Europea.
També hi ha la possibilitat de subscriure’s a un document o al resultat d’una cerca, de manera que, quan la norma o el resultat de la cerca seleccionats tinguin una modificació, els usuaris rebran una alerta a la bústia del correu electrònic facilitat.
Des del punt de vista terminològic i del llenguatge juridicoadministratiu, l’interès d’aquest Portal es concentra, especialment, en la pestanya «Eines», que conté, entre altres informacions, referències bibliogràfiques i documents sobre principis, criteris i recomanacions per a l’elaboració i la revisió de les normes («Tècnica i qualitat normativa»), i un breu glossari de trenta-cinc termes jurídics emprats en el Portal amb les definicions corresponents («Glossari»).
Saludem, doncs, ben cordialment aquesta nova iniciativa de la nostra Administració, tan necessària per als especialistes del dret com útil per als ciutadans en general.
Josep M. Mestres (Servei de Correcció Lingüística de l’Institut d’Estudis Catalans)
15 febr. 2011
Els usuaris habituals del Cercaterm ja deveu haver vist que el web del TERMCAT s’ha renovat. Un dels principals avantatges d’aquests renovació són les millores en l’accés al Cercaterm, que ara no requereix autenticació prèvia, i en les possibilitats d’afinar la cerca restringint la llengua, la categoria lèxica, l’àrea temàtica, el camp (denominació, definició o nota), etc., o ampliant les possibilitats d’obtenció de resultats mitjançant la cerca per aproximació.
Una de les conseqüències d’aquesta millora en l’accés al Cercaterm és la possibilitat de fer-ne un motor de cerca directa (search engine plugin) per a poder accedir-hi més fàcilment sense necessitat d’accedir prèviament al web del recurs (és a dir, sense haver de tenir una finestra del nostre navegador oberta amb aquest recurs). Els Serveis Lingüístics de la UB han creat un motor de cerca directa per al recurs Cercaterm que trobareu al web de Mycroft Project (repositori universal de motors de cerca directa) o dins de la selecció que els Serveis Lingüístics de la UB ofereixen des de la pàgina Motors de cerca directa per a facilitar-ne la instal·lació.
Àngels Egea (Serveis Lingüístics, UB)